Faire tourner un modèle IA chez soi avec Ollama
Utiliser un LLM sans envoyer ses données ailleurs, c'est possible. Ollama et Open WebUI permettent de faire tourner un modèle IA chez soi.


Dans un précédent article, on a vu ce qu’est l’Intelligence Artificielle, ce qu’elle peut apporter au quotidien, mais aussi pourquoi il reste important de garder un œil sur les données qu’on lui confie.

La suite logique, c’est donc de passer à l’étape suivante : faire tourner un modèle directement chez soi, dans son propre environnement. Aujourd’hui, il existe des outils qui rendent cela bien plus accessible qu’on ne pourrait l’imaginer, y compris dans un homelab.
Les avantages d’un LLM en local
Faire tourner un LLM en local, ce n’est pas seulement une question de vie privée ou d’autonomie, même si ces deux aspects comptent beaucoup. C’est aussi une façon de reprendre la main sur l’outil : choisir son modèle, décider comment il tourne, comment il est exposé et comment il s’intègre au reste du homelab.
Au quotidien, cela évite de dépendre d’un service tiers, d’un compte à créer ou d’un abonnement pour les usages les plus simples. Et pour celles et ceux qui aiment expérimenter, c’est aussi un très bon moyen de tester plusieurs modèles, d’ajuster les réglages et de construire quelque chose de vraiment adapté à ses besoins.
Pour mettre cela en place, on va s’appuyer sur deux outils complémentaires : Ollama, qui va gérer les modèles de langage, et Open WebUI, qui apporte une interface web moderne pour une utilisation au quotidien.
Ollama est un outil qui permet de télécharger et d'exécuter des modèles de langage (LLM) en local. Il expose une API compatible OpenAI, ce qui le rend facilement intégrable avec d'autres outils. En pratique, on lui demande un modèle, il le télécharge puis le met à disposition.

Open WebUI est une interface web qui vient se connecter à Ollama. Elle donne accès à une interface conviviale, à la gestion de plusieurs modèles, à l’historique des conversations, ainsi qu’à quelques réglages utiles comme le system prompt ou la température.

Quel matériel faut-il pour faire tourner un LLM en local ?
Avant de passer à l’installation, il faut quand même garder une chose en tête : un LLM peut tourner sur des machines très différentes, mais pas du tout avec le même confort. Entre un petit modèle lancé sur CPU, un modèle plus costaud exploité avec un GPU, ou encore les machines récentes équipées de NPU, l’expérience peut vite changer.
Dans tous les cas, le point le plus important reste la mémoire disponible et la taille du modèle choisi. Plus un modèle est gros, plus il demandera de ressources pour être chargé et utilisé dans de bonnes conditions.
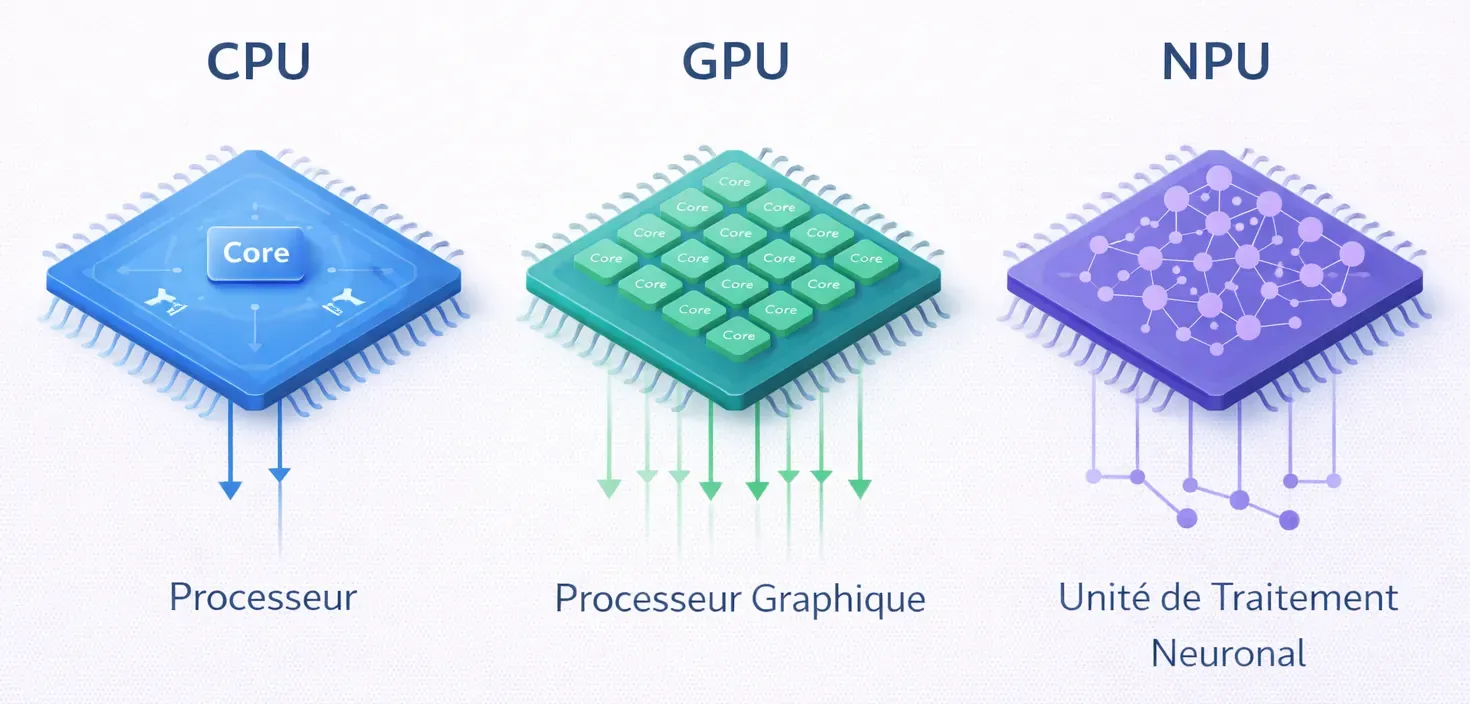
Le CPU est la solution la plus simple pour démarrer. Il ne demande pas de matériel particulier et suffit largement pour découvrir Ollama, lancer de petits modèles ou faire quelques tests. En revanche, dès que l’on monte en taille, les calculs deviennent plus lourds, la mémoire est davantage sollicitée et les temps de réponse s’allongent rapidement.
Le GPU, lui, change souvent complètement l’expérience. Comme il est conçu pour exécuter énormément d’opérations en parallèle, il est bien plus à l’aise sur ce type de charge. Résultat : les réponses arrivent plus vite, l’ensemble est plus fluide, et les modèles intermédiaires ou plus lourds deviennent bien plus agréables à utiliser. Dans un homelab, c’est souvent ce qui fait la vraie différence dès que l’on veut aller un peu plus loin.
Les NPU (Neural Processing Unit), de leur côté, sont des accélérateurs spécialisés pour certains traitements liés à l’intelligence artificielle. L’idée est d’exécuter ces tâches localement avec une consommation plus faible qu’un GPU classique, notamment sur les machines récentes. C’est très prometteur, mais pour un usage homelab avec Ollama, ce n’est pas encore l’option la plus simple ni la plus répandue aujourd’hui.
Pour résumer simplement : un CPU suffit pour découvrir le fonctionnement d’un LLM local avec des modèles compacts. Un GPU offrira une expérience bien plus confortable pour un usage régulier. Quant au NPU, c’est surtout une piste intéressante à suivre, mais encore assez secondaire dans un homelab classique.
Comprendre la taille des modèles et les tokens
Quand on commence à regarder les modèles LLM disponibles, on croise rapidement deux notions importantes : la taille du modèle, généralement exprimée en B pour milliards de paramètres, et les tokens. Ce sont deux repères essentiels pour mieux comprendre à la fois les capacités d’un modèle et les performances que l’on peut en attendre en local.
La taille d’un modèle donne une idée de sa complexité et de ce qu’il peut potentiellement traiter. En règle générale, plus un modèle est gros, plus il peut être pertinent et polyvalent, mais plus il demandera aussi de mémoire et de puissance pour fonctionner correctement.
Les tokens, eux, correspondent aux unités de texte manipulées par le modèle. Ce ne sont pas exactement des mots : un mot peut correspondre à un ou plusieurs tokens selon la langue, la ponctuation ou la façon dont le texte est découpé. Plus un prompt, une conversation ou un document contient de tokens, plus le traitement demandera de ressources.
Impact des tokens en pratique :
| Tokens | Ce que cela représente | Impact en local |
|---|---|---|
| 1 000 | prompt simple ou petit échange | très léger |
| 4 000 | conversation plus longue ou texte conséquent | généralement fluide |
| 8 000 | échange riche ou document déjà long | demande plus de mémoire |
| 16 000 et + | gros contexte ou usage avancé | peut vite alourdir l’inférence |
Il faut surtout voir cela comme un ordre d’idée. Un token ne correspond pas exactement à un mot, et l’impact réel dépendra aussi du modèle utilisé, de sa quantification et du matériel disponible.
Justement, la quantification est un processus qui réduit la précision des calculs pour diminuer la mémoire nécessaire. Un modèle 7B non quantifié peut demander 14 Go de RAM, mais en version Q4 (4 bits), il passe sous les 4 Go. C'est ce qui permet de faire tourner des modèles corrects sur des machines plus modestes.
Exemples de ressources selon la taille du modèle :
| Taille modèle | RAM conseillée | Confort sur CPU | Confort avec GPU |
|---|---|---|---|
| 1B à 3B | 4 à 8 Go | agréable | très fluide |
| 7B à 8B | 8 à 16 Go | utilisable | confortable |
| 13B à 14B | 16 à 32 Go | assez lent | bon si GPU adapté |
| 20B à 24B | 32 Go et plus | peu confortable | intéressant avec un bon GPU |
| 30B et plus | 64 Go et plus | très difficile | réservé aux machines plus musclées |
Ici aussi, ces valeurs restent surtout là pour donner un ordre d’idée. Entre la quantification du modèle, la RAM réellement disponible, le processeur, la vitesse du stockage ou la présence d’un GPU, l’expérience peut varier assez sensiblement d’une machine à l’autre.
En résumé, plus le modèle est gros et plus le contexte manipulé est long, plus la machine devra suivre. D’où l’intérêt de choisir un modèle cohérent avec ses ressources et ses usages.
Prérequis
Avant de commencer l'installation d'Ollama, il faudra disposer au minimum de :
- une machine avec 4 vCPU et 8 Go de RAM pour un modèle 3B
- un système Debian 13 ou Ubuntu 24.04 à jour, avec Docker installé
Pour un usage plus fluide, notamment avec un modèle 7B quantisé, je recommande plutôt 8 vCPU et 16 Go de RAM.
Dans mon cas, je suis parti sur un LXC Ubuntu 24.04 avec 8 vCPU et 12 Go de RAM sur un NUC MS-01 (sans GPU dédié).
Pour vous donner une idée des performances, llama3.2 3B génère environ 15 tokens par seconde, ce qui donne une réponse quasi instantanée alors qu'un modèle 7B descend autour de 5-7 tok/s, ce qui reste acceptable mais moins fluide. C'est le compromis pour faire tourner tout ça en local.
Déployer Ollama avec Open WebUI
Dans ce guide, je vais présenter deux approches : une installation d’Ollama sous Docker, puis une installation directe sur le système avec le script officiel. Dans les deux cas, Open WebUI sera déployé sous Docker pour fournir l’interface web.
Option 1 : installation d'Ollama sous Docker
Commencez par créer le dossier qui accueillera la stack :
mkdir -p /opt/stacks/ollama && cd /opt/stacks/ollamaCréez le fichier compose.yaml et collez-y le contenu suivant :
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- 11434:11434
volumes:
- ./ollama_data:/root/.ollama # Répertoire où seront stockés les modèlesLancez ensuite la stack :
docker compose up -dOption 2 : installation directe d’Ollama sur le système
Si vous préférez installer Ollama directement sur la machine, la méthode la plus simple consiste à utiliser le script officiel fourni par le projet :
curl -fsSL https://ollama.com/install.sh | shUne fois l’installation terminée, vous pouvez vérifier qu’Ollama est bien présent :
ollama -vPuis démarrer le service manuellement si nécessaire :
ollama serveUtilisation d'Ollama en ligne de commande
Avant même de passer à Open WebUI, on peut tester Ollama directement en ligne de commande. C'est rapide, et ça permet de vérifier que tout fonctionne.
Pour commencer, on va lancer un premier modèle simple : llama3.2, la commande va télécharger le modèle puis lancer une conversation interactive.
Si Ollama a été installé directement sur le système, la commande est la suivante :
ollama run llama3.2Si Ollama tourne sous Docker, il faudra exécuter la commande à l’intérieur du conteneur :
docker exec -it ollama ollama run llama3.2Vous pouvez alors poser une question simple, par exemple :
Explique simplement ce qu’est un homelab en 5 lignes.
Ollama répond directement dans le terminal, ce qui permet de tester rapidement le comportement du modèle sans interface supplémentaire. Si vous souhaitez quitter la conversation, il suffit d’utiliser Ctrl + D ou de taper /bye.

Cette première étape est intéressante, car elle permet de valider à la fois le téléchargement du modèle, son chargement en mémoire et le bon fonctionnement général d’Ollama avant d’aller plus loin.
Installation d'Open WebUI
Si vous avez déjà déployé Ollama sous Docker, le plus simple est simplement d’ajouter le service open-webui au fichier compose.yaml déjà existant, afin de conserver les deux composants dans la même stack.
Si, en revanche, Ollama a été installé directement sur le système, il faudra créer une stack dédiée à Open WebUI.
mkdir -p /opt/stacks/openwebui && cd /opt/stacks/openwebuiCréez le fichier compose.yaml et collez-y le contenu suivant :
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
# Décommentez les 2 lignes suivantes si vous ajoutez Open WebUI à la stack d'Ollama
# depends_on:
# - ollama
ports:
- 3000:8080
environment:
- OLLAMA_BASE_URL=http://127.0.0.1:11434 # Remplacez l'URL par http://ollama:11434 si vous ajoutez Open WebUI à la stack d'Ollama
volumes:
- ./openwebui_data:/app/backend/data # Répertoire où seront stockés l'historique et la configurationLancez ensuite la stack :
docker compose up -dUne fois Open WebUI déployé, l’interface devient accessible depuis un navigateur à l’adresse suivante http://IP_DU_SERVEUR:3000.
Utilisation d'Open WebUI
Au premier lancement, Open WebUI vous proposera de créer un compte administrateur. Une fois cette étape passée, on arrive sur un environnement bien plus confortable pour un usage quotidien. Pour celles et ceux qui ont déjà utilisé ChatGPT ou Claude, vous ne serez pas dépaysés : on y retrouve une logique très proche, avec une zone de chat, un historique des échanges, la gestion des modèles et quelques réglages utiles. C’est ce qui rend l’ensemble plus agréable à utiliser au quotidien. Open WebUI permet notamment de basculer entre les modèles en un clic, c'est quand même un gros + par rapport à la CLI.
Si Ollama est bien connecté, plusieurs cas de figure sont possibles. Si vous avez déjà téléchargé llama3.2 en ligne de commande, le modèle peut déjà apparaître dans l’interface et être directement sélectionnable. Sinon, il faudra le récupérer depuis Open WebUI en choisissant un modèle disponible via Ollama.
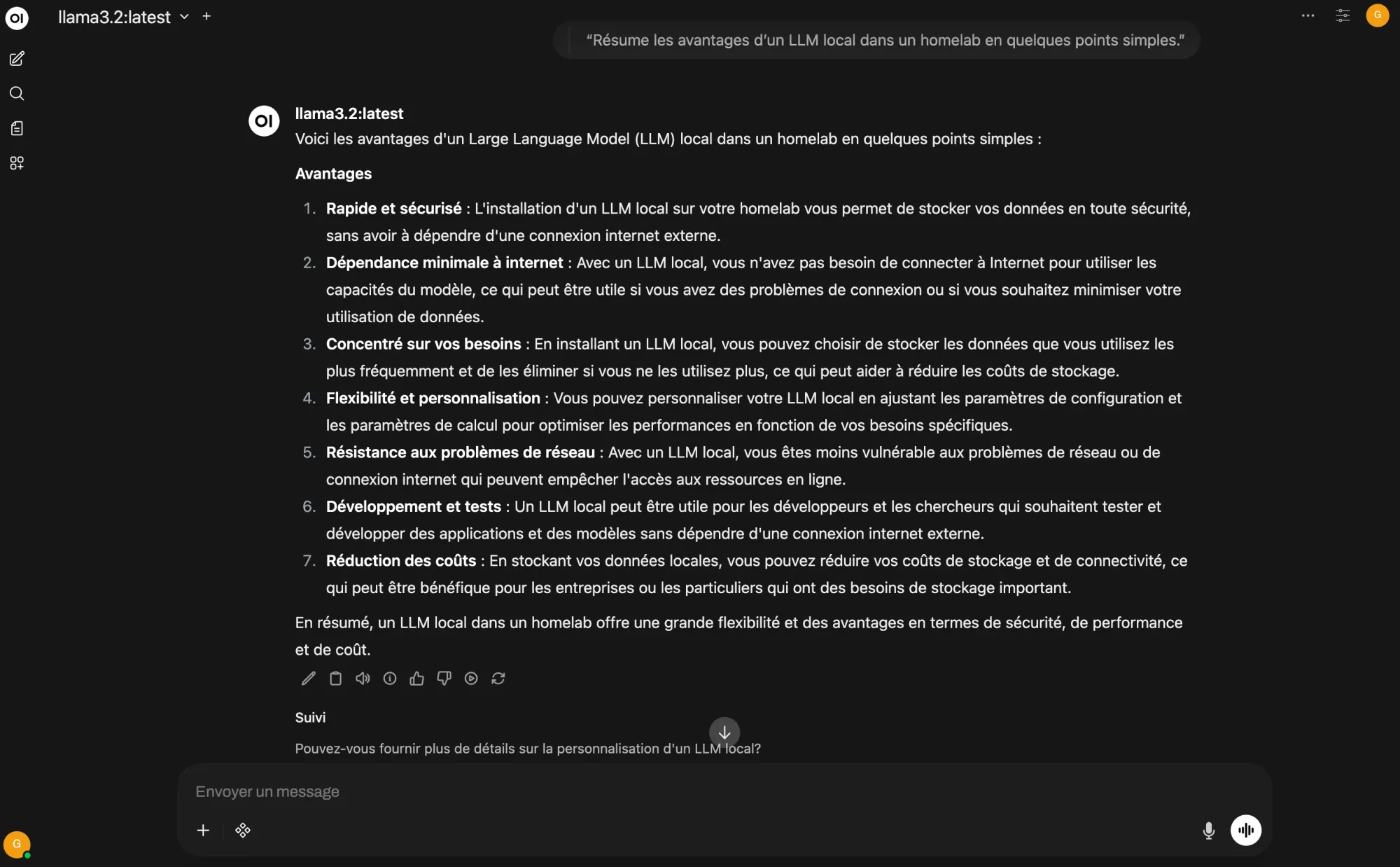
Vous pouvez alors démarrer une nouvelle conversation et tester, par exemple :
Résume les avantages d’un LLM local dans un homelab en quelques points simples.
Vous trouverez la liste de tous les modèles téléchargeables sur le site d'Ollama :

Dans les réglages qui valent vraiment le coup d’œil, le system prompt et la température sont sans doute les deux plus utiles au départ. Le premier permet de cadrer le comportement du modèle, tandis que la seconde joue sur la créativité et la stabilité des réponses. Avec seulement ces deux paramètres, on peut déjà adapter assez facilement un modèle à son usage.
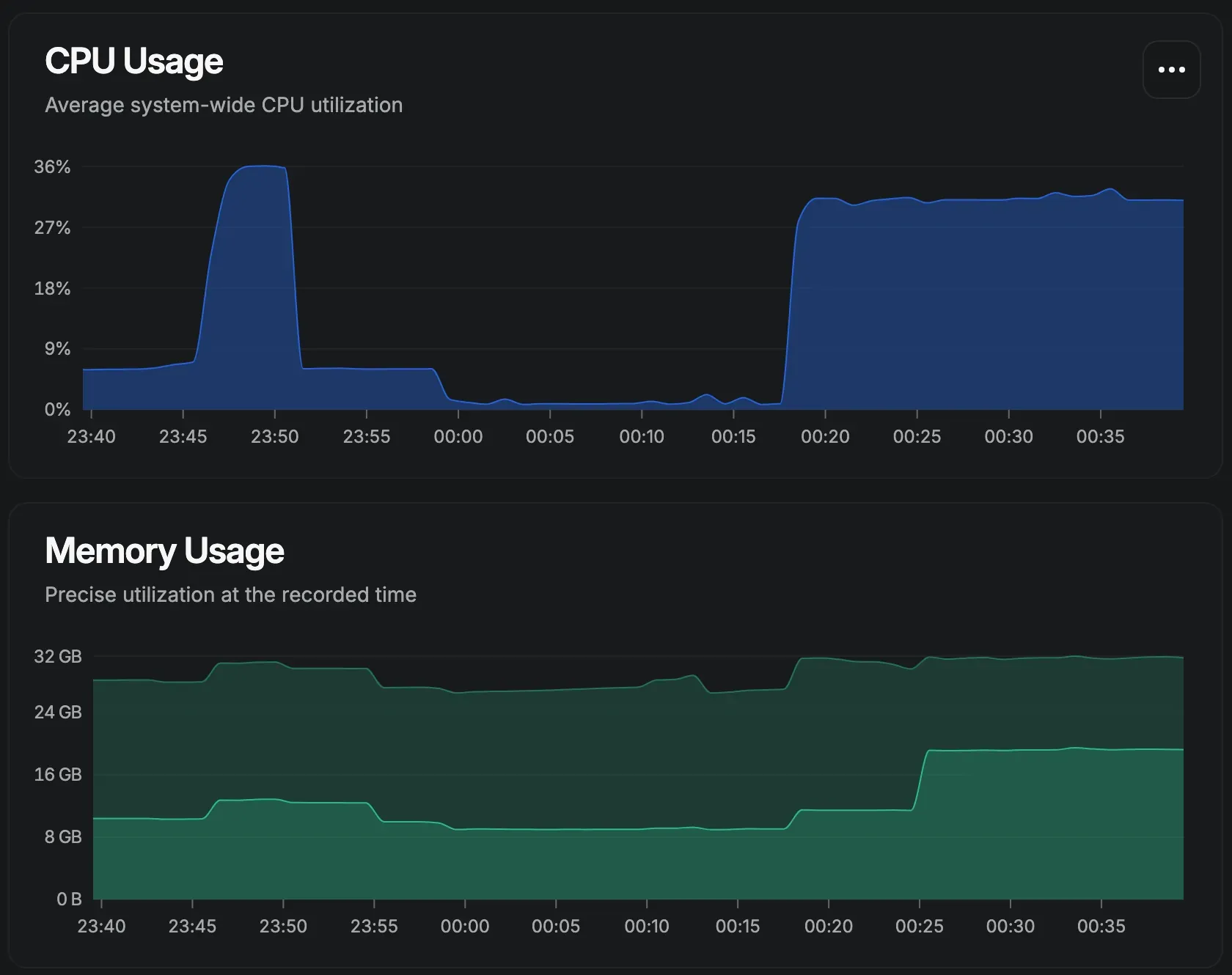
Pour donner un aperçu plus concret de ce que cela représente en pratique, voici une capture de l’utilisation des ressources pendant l’exécution d’un modèle en local. On voit assez vite que, sans GPU, le CPU et la RAM sont fortement sollicités, ce qui explique pourquoi les performances peuvent vite varier selon la machine utilisée.
Bonus : estimer la compatibilité de son matériel avec llmfit
Si vous hésitez encore sur les modèles à télécharger ou que vous voulez simplement vérifier ce qui peut raisonnablement tourner sur votre configuration, llmfit peut vous faire gagner du temps.
Cet outil en ligne de commande analyse votre matériel (CPU, RAM disponible, GPU si présent) et vous indique quels modèles sont compatibles, avec une estimation des performances attendues. C'est particulièrement utile pour éviter de télécharger un gros modèle qui ne tournera jamais correctement, ou au contraire pour découvrir qu'on peut se permettre d'aller un peu plus loin que prévu.
L'installation se fait en quelques secondes, et l'utilisation reste simple et efficace.
Conclusion
À l’usage, ce qui ressort surtout, c’est qu’Ollama et Open WebUI rendent les LLM locaux beaucoup plus simples à prendre en main qu’on pourrait l’imaginer au départ. Une fois l’installation faite, on obtient rapidement quelque chose de concret, utilisable, et surtout facile à faire évoluer selon sa machine et ses besoins.
De mon côté, c’est aussi ce que j’ai trouvé intéressant : on commence avec un simple test, puis on se prend vite au jeu à essayer plusieurs modèles, comparer les réponses, ajuster les réglages et voir jusqu’où la machine peut suivre. On comprend aussi beaucoup mieux les limites du matériel, et ce que change réellement le fait de faire tourner un modèle chez soi.
C’est d’ailleurs ce qui m’a poussé à aller un peu plus loin, avec l’achat d’un Mac mini M4 que je compte dédier à cet usage. L’idée est d’avoir une machine compacte, discrète et toujours disponible pour continuer à explorer les possibilités offertes par les LLM en local dans de bonnes conditions.
Si vous aussi vous avez tenté l'expérience ou souhaitez tester de faire tourner une IA chez vous, n'hésitez pas à partager votre ressenti en commentaire ou à venir en discuter sur le groupe Telegram.